


Since the beginning of the pandemic, our columnist and digital enthusiast Markus Sekulla has been fascinated by how digital solutions could minimize the impact of the crisis. Today, the focus is on the technical possibilities of making accurate assumptions about the future development of the pandemic.

Why should we humans engage in activities that machines are clearly better at? Often a little nostalgia comes into play: After all, I've always made my own shopping list by hand. The fact that an AI now analyzes my refrigerator and knows what I've always eaten in June and orders my purchase accordingly and has it delivered, all of course at a time when I'm usually at home, all sounds a bit spooky, but also quite practical.
Of course, no machine knows when I might have a Snickers craving. The system just doesn't know certain parameters... and somehow this makes life creative, beautiful and worth living. We like to make our own decisions, also for the reason that we overestimate ourselves. An AI would tell me that a lot of sugar stands in the way of my general life plan. My human self doesn't see the problem there. But, large amounts of data very rarely lie.
And what is the same for my kitchen and big things like Covid-19 is that you have to read data correctly, and that is not always easy, not to say very difficult. That data from the past can often predict developments in the future is something we have also seen in the last 18 months in the Corona pandemic. Many data models would have been approximately true - such as the utilization of hospital beds in some regions - if no countermeasures had been taken.
The problem that often exists is having, taking, and reading the right data, especially when it comes to the spread of viral diseases. A well-known case is the Google Flu Trends project, which between 2009 and 2015 tried to predict flu outbreaks based on Google search inquires. In the beginning with good success. However, without adapting to the changing search behavior of people, the flu waves were overestimated from 2011. This would certainly be similarly difficult in the case of the coronavirus, since network activity on Google and Twitter has fluctuated greatly since the beginning of the pandemic. If Google Trends were used for an initial assessment, there would not have been a second or third wave in Germany.
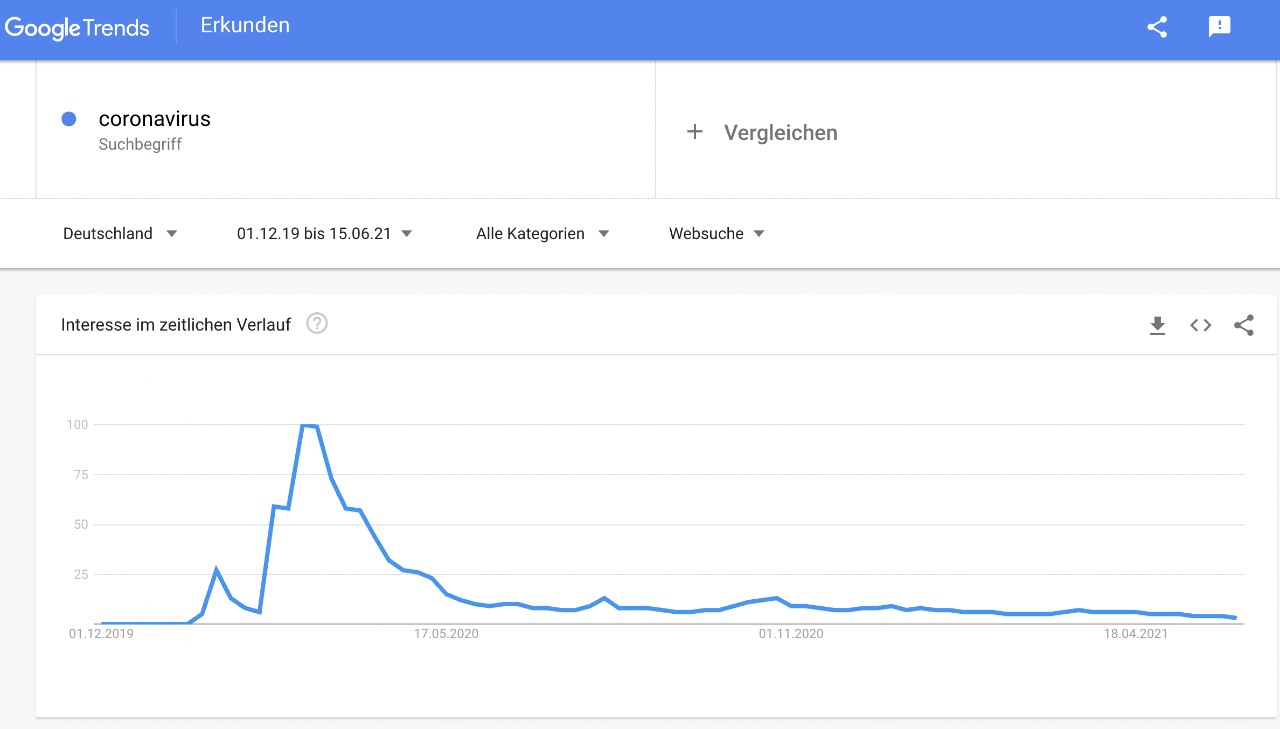
More relevant data is therefore needed to indicate outbreaks of Covid-19. With nowcasting, for example, one can infer quite accurately from past data to today, even though no diseases have been reported yet. To calculate into the future beyond that, we need to step up our game a notch. A study from Taiwan, for example, used four statistical and deep learning systems to make predictions:
Unfortunately, the results were only partially accurate and the systems delivered different results for specific conditions (i.e. different countries). If you want to dive deeper into this topic, we recommend the study (A COVID-19 Pandemic Artificial Intelligence-Based System With Deep Learning Forecasting and Automatic Statistical Data Acquisition: Development and Implementation Study). Check the web for similar studies, it’s interesting, I promise.
An artificial intelligence is (today) as good as the people who create and/or feed it. For the eternal dream of mankind - predicting the future - the perfect data sets are often missing, if they exist at all. Therefore, today we have the support of AI in the fight against Corona, but it is not yet reliable enough, at least in predicting eruptions.
In the context of AI and Covid-19 the following links might also interest you:
Test without test? Artificial intelligence recognizes Covid19 already by coughing
https://next.ergo.com/en/AI-Robotics/2020/AI-test-Covid19-coughing.html
Early Covid19 diagnosis with the help of AI
https://next.ergo.com/en/AI-Robotics/2021/Covid19-Diagnostics-AI-Artificial-Intelligence.html
Text: Markus Sekulla
Most popular